問答集生成¶
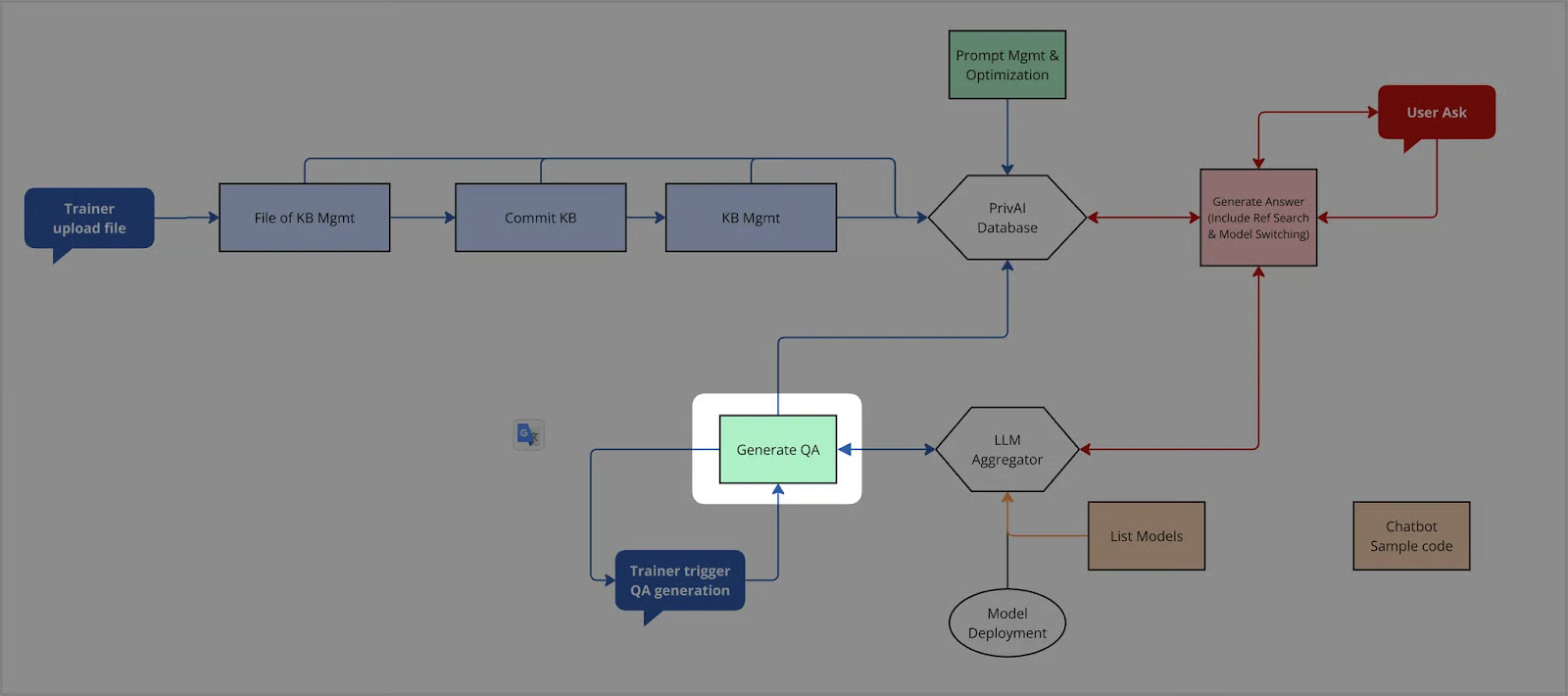
此 API 用於根據指定的 Fileset,自動生成問答集(QA Pairs),並輸出為標準格式的 QA 檔案,供後續人工校對、prompt 測試或模型訓練使用。
系統會根據檔案中的語意段落:
-
自動擷取可能的問題點(如定義、規則、流程)
-
為每個段落生成一筆問題與參考答案
-
統整成 JSON / CSV 等格式,作為一組完整的 QA 集合
curl -X 'POST' \
'http://127.0.0.1:8000/v1/qa/generate?fileset_id={fileset_id}' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <your-api-key>' \
-H 'Content-Type: application/json' \
-d '{
"model_name": "ace-1-24b-reasoning-v1",
"extract_model_name": "ace-1-24b-reasoning-v1",
"temperature": 0.7,
"target_amount": 1,
"on_oversize": "fail"
}'
Request Headers¶
| Key | Value |
|---|---|
| Request Method | POST |
| accept | application/json |
| Authorization | Bearer |
Query Parameters¶
| Field | Type | Note | Required |
|---|---|---|---|
| fileset_id | string | uuid | true |
Request Payload¶
{
"model_name": "ace-1",
"extract_model_name": "ace-1",
"temperature": 0.7,
"target_amount": 1,
"on_oversize": "fail"
}
Field Explanation
| Field | Type | Detail | Required |
|---|---|---|---|
| model_name | string | 選擇 LLM Model 來產生問答集 | false |
| extract_model_name | string | false | |
| temperature | string | 0.0-1.0,控制生成文字「隨機性」 | false |
| traget_amount | float | 1~3,用於決定從整個檔案中生成多少 QA Pair。系統會依據每約 500 個字生成一個 QA,並乘上此數值。例如,設定為 1 時,每約 500 字會生成一個 QA Pair。每個檔案最多自動生成 50 個 QA Pair。 | false |
| on_oversize | string | 處理段落過長的方式,包含 fail、split,若使用 split 則會將段落分開。 | true |
¶

Response Body¶
{
"filename": "QA_b9f375f8-048f-4d5a-a3ec-63b7f062f074.xlsx",
"bytes": 4925,
"purpose": "user_data",
"id": "792b40a2-8128-4a08-b5fc-517f040108fc",
"metadata": {
"fail_reason": null,
"fail_detail": {}
},
"created_at": "2025-01-01T01:20:00.000Z",
"expires_at": null,
"object": "file",
"state": "draft",
"filetype": "string",
"page_count": 0,
"failed_page_numbers": [
0
],
"has_hq_result": true,
"has_lq_result": true,
"has_std_result": true,
"used_quality": "HQ",
"failed_file_ids": [],
"error_message": ""
}
Field Explanation
包含 「提示詞物件」章節的內容。
| Field | Detail |
|---|---|
| failed_file_ids[] | 失敗之檔案唯一鍵列表 |
| error_message | 錯誤訊息 |